題目
LeetCode 146 的名稱就叫 LRU Cache,算是教科書等級的題目,希望你可以實作一個 cache,在內部的 Cache Key 有著透過 LRU 演算法的淘汰機制(最久沒影使用的 Key 會優先淘汰)。
時間複雜度限制 get 和 set 都要 O(1)。
思路
首先複習一下 LRU 的 get 和 set 要做的事情。為了實現 LRU,每個 key 必須要跟著一個 priority(優先度)。
- get 時要把該 key 的 priority 拉到最高,讓這個 key 在刪除時永遠是最後一個被考慮的。
- put 時,要維護並檢查目前的 capacity(容量),若 capacity 不足,則需要把 priority 最低的 cache 刪除。
這兩件事情都要在 O(1) 內達成。
Hash Map (Dictionary)
Dictionary 是 Python 實作的 Hash map,並且天生防止了 Hash collision,又擁有 Hash Map O(1) 存取的特性,因此很適合拿來做 cache。
然而光是用一個 Hash Map 沒辦法 O(1) 找出 priority 最小的 key 並刪除。
Linked List
Linked List 中的 Doubly Linked List 具有 O(1) insert / delete 的特性,可以透過讓 Node 的位置來表示優先度,每次 get 時,把該 Node 放到「第一個」,而每次 put 時,若 capacity 不足則移除「最後一個」Node 所代表的 Key,達到在 O(1) 時間內維護 priority。
但如果要查找某個 key 代表的 Node,單用 Linked List 只能達到 O(n) 的時間複雜度,因為要遍歷 List 去尋找 Node。
Linked List 搭配 Hash Map
上面提到的兩個資料結構相輔相成。兩個都使用,就能達到 O(1) 存取和 O(1) 維護 priority。
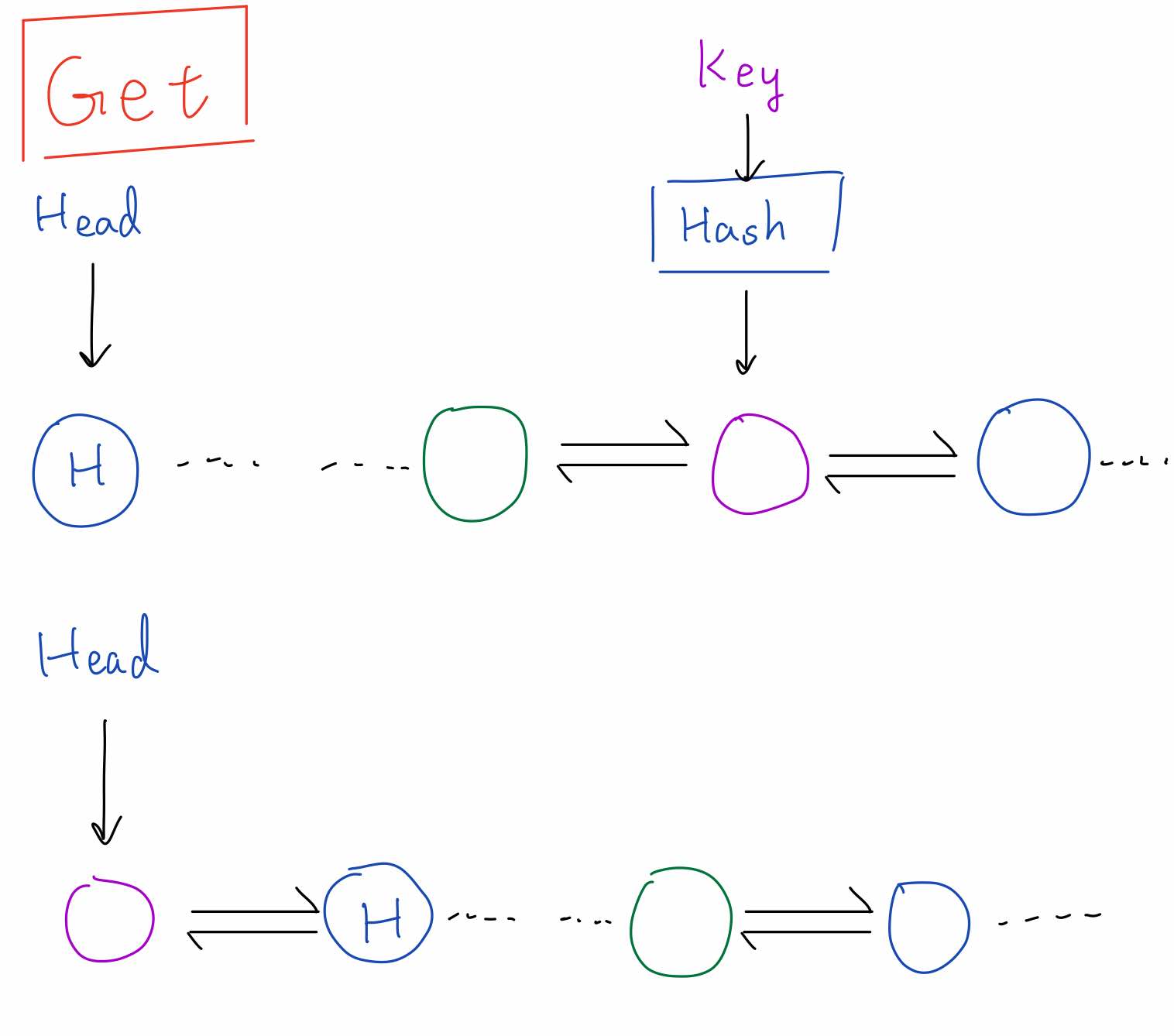
可以參考這個示意圖,get 的時候透過 hash map 找到 Node,並把該 Node 搬到 head 來維護 priority:
實作
先來定義 Linked List 裡面放的 Node:
class Node:
def __init__(self, key: int=None, val: int=None):
self.key = key
self.val = val
self.next = None
self.prev = None
接著是 LRU Cache 的部分。
在頭尾都使用 dummy node,來減少繁瑣的邊界條件處理,也算是 Linked List 常用的技巧了。
有了 dummy node,原本我們的「第一個」Node,就是 head 的下一個。而「最後一個」Node,就是 tail 的上一個。
class LRUCache:
def __init__(self, capacity: int):
self.map = {}
self.head = Node()
self.tail = Node()
self.capacity = capacity
# 別忘了把頭尾接起來
self.head.append(self.tail)
這裡偷偷先使用了 append 這個方法。他應該要是個可以幫我們把某個 Node 和另一個 Node 連在一起的 method,回到 Node Class 補上:
class Node:
...
def append(self, other: 'Node') -> None:
self.next = other
other.prev = self
接著來處理 LRU cache 的核心 method。從 get 先開始:
class LRUCache:
...
def get(self, key: int) -> int:
# cache miss
if key not in self.map:
return -1
# cache hit,調整 priority
node = self.map[key] # Hash map 的 O(1) 查找
node.pull() # 又是一個新方法,可以想像成把這個 Node 拉出來
node.append(self.head.next) # 把這個 Node 拉到「第一個」,也就是把原本的第一個接在後面
self.head.append(node) # 然後接到 dummy head 後方
# 回傳
return node.val
這邊又偷偷用了一個新方法:pull。他應該要是個可以讓我們把這個 Node「取出」原本的位置,把他原先前後的 Node 接起來:
class Node:
...
def pull(self) -> None:
if self.next:
self.next.prev = self.prev
if self.prev:
self.prev.next = self.next
到這邊已經完成一半了。
接下來是加入 key 和刪除最少使用的 node 的部分:
class LRUCache:
...
def put(self, key: int, value: int) -> None:
# 如果已經有了,就不需要插入新的 Node,只需要更新值就好
if key in self.map:
node = self.map[key]
node.val = value
node.pull()
else:
# initialize 新的 Node:
self.map[key] = Node(key, value)
if self.capacity > 0:
self.capacity -= 1
else:
# capacity 不夠,要刪除 LRU
discard = self.tail.prev # 因為 capacity > 1,一定是非 dummy node
discard.pull() # 斷開連結!
del self.map[discard.key] # 在 Node Class 定義時記住的 key 派上用場了
del discard
# 當然,和 get 一樣,剛使用過/加入的 Node 也要放在「第一個」
node = self.map[key]
node.append(self.head.next)
self.head.append(node)
完整 Code
class Node:
def __init__(self, key: int=None, val: int=None):
self.key = key
self.val = val
self.next = None
self.prev = None
def append(self, other: 'Node') -> None:
self.next = other
other.prev = self
def pull(self) -> None:
if self.next:
self.next.prev = self.prev
if self.prev:
self.prev.next = self.next
class LRUCache:
def __init__(self, capacity: int):
self.map = {}
self.head = Node()
self.tail = Node()
self.capacity = capacity
# 別忘了把頭尾接起來
self.head.append(self.tail)
def get(self, key: int) -> int:
# cache miss
if key not in self.map:
return -1
# cache hit,調整 priority
node = self.map[key] # Hash map 的 O(1) 查找
node.pull() # 又是一個新方法,可以想像成把這個 Node 拉出來
node.append(self.head.next) # 把這個 Node 拉到「第一個」,也就是把原本的第一個接在後面
self.head.append(node) # 然後接到 dummy head 後方
# 回傳
return node.val
def put(self, key: int, value: int) -> None:
# 如果已經有了,就不需要插入新的 Node,只需要更新值就好
if key in self.map:
node = self.map[key]
node.val = value
node.pull()
else:
# initialize 新的 Node:
self.map[key] = Node(key, value)
if self.capacity > 0:
self.capacity -= 1
else:
# capacity 不夠,要刪除 LRU
discard = self.tail.prev # 因為 capacity > 1,一定是非 dummy node
discard.pull() # 斷開連結!
del self.map[discard.key] # 在 Node Class 定義時記住的 key 派上用場了
del discard
# 當然,和 get 一樣,剛使用過/加入的 Node 也要放在「第一個」
node = self.map[key]
node.append(self.head.next)
self.head.append(node)
其他解法
OrderedDict
對 Python 夠熟的人,也許會想到 collections 中有個 OrderedDict,key 會按照加入的順序排列,並提供了 move_to_end 調整 key 順序,和 popitem 來移除第一個 key。其實就是幫你把上面的方法包裝好了…可以直接使用,雖然就失去了自己實作 LRU 的意義了(就像你用 Python List 實作 Stack 一樣,快但是沒有練習到)。
class LRUCache:
def __init__(self, capacity: int):
self.capacity = capacity
self.map = collections.OrderedDict()
def get(self, key: int) -> int:
if key not in self.map:
return -1
value = self.map[key]
self.map.move_to_end(key)
return value
def put(self, key: int, value: int) -> None:
if key in self.map:
self.map[key] = value
self.map.move_to_end(key)
else:
self.map[key] = value
if self.capacity > 0:
self.capacity -= 1
else:
self.map.popitem(last=False) # 移除第一個
Dictionary
Python 3.7 之後,Dictionary 保證了 key 會照著插入順序排列。可以透過 O(1) 的 delete 和 insert 來重置 key 在 Dictionary 的順序,讓第一項是 priority 最低的項目,並且在 capacity 不足時,刪除第一個就好:
class LRUCache:
def __init__(self, capacity: int):
self.capacity = capacity
self.map = {}
def get(self, key: int) -> int:
if key not in self.map:
return -1
value = self.map[key]
del self.map[key]
self.map[key] = value
return value
def put(self, key: int, value: int) -> None:
if key in self.map:
del self.map[key]
self.map[key] = value
else:
self.map[key] = value
if self.capacity > 0:
self.capacity -= 1
else:
item_view = self.map.items()
iterator = iter(item_view)
key, _ = next(iterator)
del self.map[key]
面試這樣寫可以證明你真的很熟 Python,但大概不容易給過吧 XD